Introduction
PyLiPD is a Python package for handling LiPD datasets.
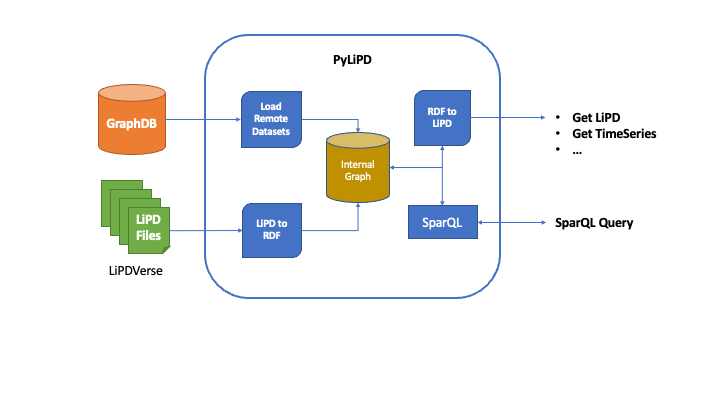
PyLiPD loads the Linked Paleo Data (LiPD), either locally or online, and converts them internally into RDF graphs for further querying. Alternatively, PyLiPD can also read an RDF Knowledge Base like GraphDB directly that is populated by the LiPD datasets converted into RDF graphs. In short, it allows you to work seamlessly with LiPD files stored on your computer, on the web or in a dedicated database meant to work with graphs.
PyLiPD can use the internal/remote graph representation to either answer SparQL queries about the datasets, or simply convert it back to LiPD, or get the TimeSeries objects across multiple datasets for further analysis by packages such as Pyleoclim or CFR.
The package makes working with the Graph representation easier. You do not need to learn SparQL to start working with PyLiPD. However, SparQL is a fast, efficient language that makes querying much easier so we won’t stop you from learning it.
In summary, PyLiPD allows you to:
Open LiPD-formatted datasets stored locally on your computer, available through a URL or our Graph Database, the LiPDGraph.
Manipulate these datasets to query information either through Pandas, SPARQL-supported APIs or SPARQL queries
Create LiPD files
PyLiPD supersedes the LiPD Python utilities which are no longer maintained. Utilities in R (LipdR) are also available. Note that although the Python and R versions offer similar functionalities, the R version is not supported by a graph and does not support the Graph Database directly.
Getting Started
Working with PyLiPD
Getting Involved
PyLiPD has been made freely available under the terms of the Apache License 2.0 and follows an open development model. There are many ways to get involved in the development of PyLiPD:
If you write a paper making use of PyLiPD, please cite it thus.
Report bugs and problems with the code or documentation to our GitHub repository. Please make sure that there is not outstanding issues that cover the problem you’re experiencing.
Contribute bug fixes
Contribute enhancements and new features
Contribute to the code documentation, and share your PyLiPD-supported scientific workflow as a (PaleoBook).